理解 Spark 的内存管理并对其进行性能优化,是迈向 Spark 高手(如 Spark APIT 认证)的必经之路。Spark 的内存管理机制(特别是 Tungsten 项目引入的堆外内存和统一内存管理)是其高效运行的基石,而合理的参数配置和代码优化则是释放性能的关键。
下面我将从内存模型原理、核心参数调优、代码与算子优化以及常见问题诊断四个方面为你深度解析。
🧠 一、Spark 内存模型深度解析
Spark 的内存管理主要针对 Executor JVM。要优化它,首先要看懂它的“钱包”是怎么划分的。
1. 内存全景图
一个 Executor 申请到的总内存(由 --executor-memory 设定,假设为 4GB)在内部被划分为多个区域,其关系大致如下:
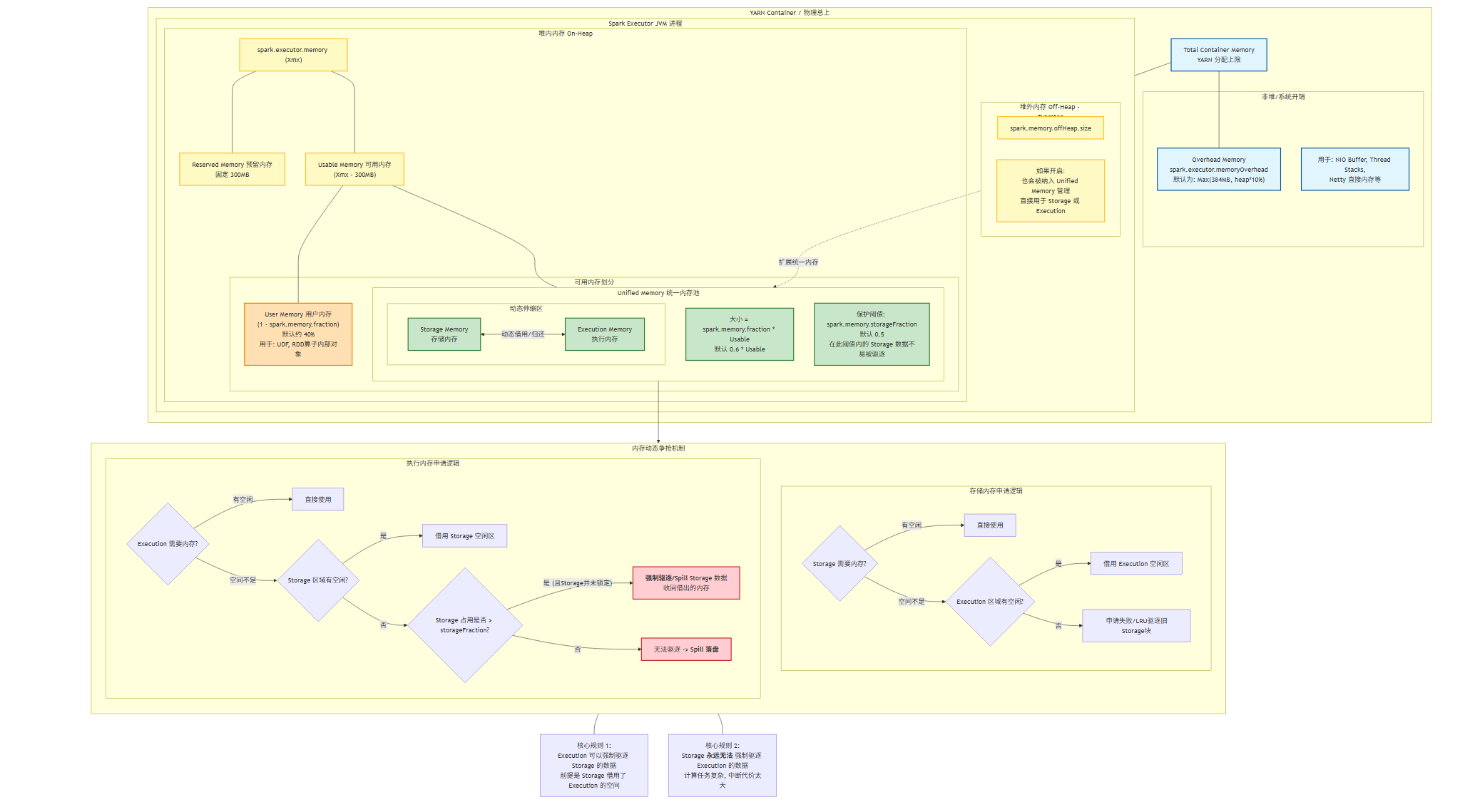
| 区域 | 大小比例 (典型) | 核心职责 | 调优关注点 |
|---|---|---|---|
| Reserved Memory | max(384MB, executor-memory * 0.1) | JVM 自身开销、字符串常量池、内部对象等。用户代码不可用。 | 通常无需调整,但设置过小的 executor-memory 会导致此部分占比过高,实际可用内存少。 |
| User Memory | (1 - spark.memory.fraction) * (Heap - Reserved) | 用户代码中创建的对象、数据结构、UDF 中的变量等。OOM 频发区。 | 优化代码,避免在算子函数中创建大量临时对象。 |
| Spark Memory (Storage + Execution) | spark.memory.fraction * (Heap - Reserved) | Spark 托管的核心区域,用于缓存和计算。 | 调优的核心战场,通过 storageFraction 调节存储与计算的平衡。 |
| Off-Heap Memory | spark.memory.offHeap.size | 堆外内存,由 Spark 直接管理,不经过 JVM GC。用于 Tungsten 的二进制数据、堆外排序等。 | 利用堆外内存可以规避 GC 停顿,但需配置 spark.memory.offHeap.enabled=true。 |
2. 统一内存管理的动态借用机制
自 Spark 1.6 起,默认使用 Unified Memory Manager,其核心思想是 “动态共享”【turn0search4】【turn0search9】:
- Execution Memory 可以借用 Storage Memory:当 Shuffle、Join 等计算任务需要更多内存时,Execution Memory 可以占用 Storage Memory 的空闲部分。如果 Storage Memory 中有数据被使用,则不能被回收(除非内存严重不足)。
- Storage Memory 只能“被动”借用 Execution Memory:Storage Memory 自身的大小由
spark.storageFraction * (Storage + Execution)定义(即一个最低保障线)。当实际存储占用低于这个线时,它可以使用 Execution Memory 的剩余空闲部分。但当 Execution Memory 需要回收这部分内存用于计算时,它会直接“抢占”。 - 原则:Execution Memory 的优先级高于 Storage Memory。计算任务(如 Shuffle)是“实时”的,必须保证其内存需求;而缓存的数据可以被驱逐到磁盘(
MEMORY_AND_DISK)或丢弃(MEMORY_ONLY)。
💡 调优启示:如果你的作业计算密集(Shuffle/Join 多),可适当调高
spark.memory.fraction(如 0.7-0.8),给 Execution Memory 更多空间。如果缓存密集,可调高spark.storageFraction(如 0.6),保证数据不被频繁驱逐。
⚙️ 二、核心参数调优指南
基于上述模型,通过调整关键参数来优化内存使用和性能。
1. 内存比例参数
这是最直接有效的调优手段。
| 参数 | 默认值 | 调优建议与场景 |
|---|---|---|
spark.memory.fraction | 0.6 | 计算密集型(Shuffle 多、Join/Sort 重):调高至 0.7~0.8,增大 Execution 内存池,减少溢写。 缓存密集型:保持 0.6 或略低。 |
spark.memory.storageFraction | 0.5 | 需要大量缓存(如多次迭代 ML 算法):调高至 0.6~0.7,为缓存提供更多保障。 极少缓存:可调低至 0.3~0.4,将更多内存留给 Execution。 |
spark.memory.offHeap.enabled | false | 开启堆外内存。设置为 true,并设置 spark.memory.offHeap.size(如 2GB)。用于 Tungsten,避免 GC 扫描大对象。 |
⚠️ 注意:
spark.memory.fraction和spark.memory.storageFraction是乘积关系,且最终受限于spark.memory.fraction。 即,Storage可用最大内存 = spark.memory.fraction * (Heap - Reserved) * spark.storageFraction。 例如,Heap=4G, Reserved=300MB,spark.memory.fraction=0.6,spark.storageFraction=0.5:Spark Memory= (4G - 300MB) * 0.6 ≈ 2.28GBStorage Memory(保障线) = 2.28GB * 0.5 ≈ 1.14GB (但最高可达 2.28GB)Execution Memory(初始) = 2.28GB - 1.14GB ≈ 1.14GB (但最高可达 2.28GB)
2. JVM 垃圾回收 (GC) 优化参数
频繁的 Full GC 是 Spark 性能杀手。可以通过 Spark 的 --conf 参数传递给 JVM。
| 参数 | 说明 | 推荐值 |
|---|---|---|
spark.executor.extraJavaOptions | 传递给 Executor JVM 的参数。 | "-XX:+UseG1GC" (推荐 G1GC,平衡吞吐与停顿)"-XX:InitiatingHeapOccupancyPercent=45" (更早触发并发标记,降低停顿)"-XX:MaxGCPauseMillis=200" (目标最大停顿时间) |
spark.yarn.executor.memoryOverheadspark.yarn.driver.memoryOverhead | YARN 模式下的堆外内存预留,用于 JVM 自身开销、字符串、NIO Buffer 等。 | 默认为 executor-memory 的 10%,最小 384MB。如果发现频繁 Container 被杀(由于超出物理内存),可显式调小此值,增加 executor-memory 的实际可用量。 |
spark.testing.memory | 用于测试的内存参数,可强制设置各部分大小。 | 调试时使用,生产环境慎用。 |
💡 GC 调优目标:减少 Full GC 频率,将停顿时间控制在几十到几百毫秒内。通过 Spark UI 的 Executors 标签页,观察 GC Time 列,如果占比很高(如 >10%),则需要优化。
🧩 三、代码与算子层面的内存优化
除了参数,编码习惯和算子选择对内存消耗影响巨大。
1. 数据序列化优化
Spark 默认使用 Java 序列化,效率低且空间占用大。
- 使用 Kryo 序列化:
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") conf.registerKryoClasses(Array(classOf[MyClass])) - 避免在 RDD 中使用未序列化的 Java 对象:尽量使用基本类型(Int, Long, String)或 Spark 提供的
Writable类型。
2. 缓存策略优化
cache()/persist() 是一把双刃剑,用好了提升性能,用不好则严重挤占 Execution 内存 导致 OOM。
- 选择合适的存储级别:
MEMORY_ONLY:只存内存,数据大时极易 OOM。MEMORY_AND_DISK:推荐。内存优先,不足则溢写到磁盘,兼顾性能与安全。DISK_ONLY:不占内存,但性能差,几乎不用。
- 及时释放缓存:用完后立即
unpersist(),避免内存长期被占用【turn0search4】。 - 优先缓存过滤后的数据:
rdd.filter(...).cache()而不是rdd.cache().filter(...)。
3. 算子选择与优化
- 优先使用“预聚合”算子:使用
reduceByKey/aggregateByKey代替groupByKey。- 原理:
groupByKey会将所有 Key 的 Value 全部拉到内存,极易 OOM;而reduceByKey在 Map 端进行局部合并,大幅减少 Shuffle 数据量【turn0search4】。
- 原理:
- 避免创建大型中间集合:
- ❌ 错误:
val list = rdd.collect()(在 Driver 上),或rdd.map(...).collect()拉取大量数据。 - ✅ 正确:使用
rdd.foreachPartition(...)对每个分区的数据进行迭代处理,避免一次性加载所有数据。
- ❌ 错误:
- 使用广播变量:在 Join 时,如果一张表很小(如 < 几百 MB),将其广播到所有 Executor,避免 Shuffle,显著减少网络和内存开销【turn0search4】。
4. 利用堆外内存与 Tungsten
- 确保
spark.sql.inMemoryColumnarStorage.enabled和spark.sql.codegen.wholeStage等参数启用(通常默认开启),这能让 Spark SQL 使用高效的 Tungsten 引擎,利用堆外内存进行编译和执行【turn0search16】。
🔍 四、诊断与排查常见内存问题
当遇到 OOM 或性能瓶颈时,如何定位原因?
1. OOM(内存溢出)错误分析
| 错误类型 | 可能原因与排查思路 |
|---|---|
java.lang.OutOfMemoryError: Java heap space | 堆内内存 OOM。 原因:Task 处理的数据量过大、缓存过多、存在大型对象。 排查:查看 Spark UI 中该 Stage 的 Task 详情,看是哪个 Task OOM。检查是否有 collect() 大数据、数据倾斜导致单个 Task 数据量暴增。调大 --executor-memory 或优化算子。 |
Container killed by YARN for exceeding memory limits | 物理内存超限(堆内 + 堆外 > Container 申请上限)。 原因: spark.executor.memory + spark.yarn.executor.memoryOverhead > YARN 队列配置的 yarn.scheduler.maximum-allocation-mb。排查:调低 spark.yarn.executor.memoryOverhead 或增大 YARN 容器内存限制。 |
java.lang.OutOfMemoryError: GC overhead limit exceeded | GC 开销过大导致 OOM。 原因:JVM 用于 GC 的时间或内存超限,通常与堆外内存使用有关。 排查:优化 GC 参数,或调整堆外内存设置。 |
2. 利用 Spark UI 诊断内存问题
- Storage 标签页:
- 查看 RDD 的缓存大小。如果一个 RDD 缓存后占用了 50% 的内存,但实际使用率很低,说明该缓存可能浪费内存,考虑降低缓存级别或释放它。
- Executors 标签页:
- Memory Metrics:关注 Used Memory 和 Peak Memory。如果接近上限,说明内存压力大。
- GC Time:关注 GC 时间 和 Full GC 次数。如果 GC Time 占 Task 总时间的 10% 以上,说明内存分配不合理或对象创建/销毁太频繁,需要优化代码或参数。
- Stages 标签页:
- 点击某个耗时长的 Stage,查看其 Tasks 列表。
- Input Size 和 Shuffle Read/Write Size:可以帮你估算单个 Task 的数据量,判断是数据倾斜还是单纯数据量过大。
💎 总结:Spark 内存优化最佳实践清单
- 资源配置:
- 根据数据量和计算类型设置合理的
--executor-memory(如 8G-16G),避免过大(GC 压力)或过小(资源浪费)。 - 根据集群总核心数设置合适的
--num-executors,确保num-executors * executor-cores充分利用集群 CPU。
- 根据数据量和计算类型设置合理的
- 参数调优:
- 开启 Kryo:
spark.serializer=org.apache.spark.serializer.KryoSerializer。 - 启用堆外内存:
spark.memory.offHeap.enabled=true。 - 动态调整内存比例:计算密集型调高
spark.memory.fraction;缓存密集型调高spark.storageFraction。
- 开启 Kryo:
- 代码优化:
- 减少对象创建:在算子函数中复用对象,避免在循环中
new。 - 使用高效算子:
reduceByKey代替groupByKey。 - 明智地使用缓存:选择合适的
StorageLevel,并及时unpersist()。 - 优先广播小表:避免不必要的 Shuffle。
- 减少对象创建:在算子函数中复用对象,避免在循环中
- 持续监控:
- 频繁查看 Spark UI:关注 Executor 的内存使用率、GC 时间和 Task 的 Shuffle 读写量。
- 根据监控数据动态调整:没有“一劳永逸”的配置,随着数据量和逻辑的变化,持续调优是关键。
💡 建议:Spark 的内存管理是一个动态平衡的过程。它需要在减少溢写/磁盘 I/O(需要更多内存) 和 **减少 GC 压力(需要更少对象、更少内存)**之间找到最佳平衡点。理解其背后的原理,能让你在调优时更有方向感,而不是盲目修改参数。